Redis 的5种数据结构都是以一个key字符串作为增删改查的一句
String
字符串是Redis中最简单的数据结构,底层实现是一个字符数组。字符串的最大长度为512MB,其本身的长度一般会比字符串实际的长度要大,这样做可以避免频繁的内存分配。当字符串的长度小于1MB时,会预留1倍字符串长度的空间。而当字符串长度大于1MB的时候,每次扩容只会多留出1MB。
结构图示:

# 新增一个字符串
set testString1 valueString1
# 查询一个字符串
get testString1
# 删除一个字符串
del testString1
# 批量新增字符串
mset testString1 valueString1 testString2 valueString2
# 批量查询字符串
mget testString1 testString2
# 新增一个字符串并设置过期时间为1s
setex testString1 1 valueString1
# 对value为int型的进行计数
set testNum 1
incr testNum //res: 2
incrby testNum 3 //res: 5
List
List在Redis中底层实现为多个ziplist双向链接的链表,当list的元素个数较少的情况。Redis会把所有的元素存放到连续存储的内存中也就是ziplist结构(ziplist也可以理解为一个链表),显而易见链表的特点是快速的插入以及删除,而查找比较慢。所以list结构多用于实现队列或栈。
结构图示:

# 从右侧新增一个元素
rpush testList1 valueString1
# 从左侧删除一个元素
lpop testList1
# 查找第一个元素,由于链表结构查询较慢不建议
lindex testList1 0
# 获取所有元素
lrange testList1 0 -1
# 获取第2个到第6个元素
ltrim testList1 1 5
#获取长度
llen testList1
Hash
Hash在Redis底层实现为较为常见的数组+链表形式。通过hash算法得到存在数组的位置,如果遇到哈希碰撞则在后面以链表的形式追加元素。在rehash的时候为了提高性能,Redis使用渐进式rehash方式,保留新旧两个hash数据,查询时候会查询两个hash数据,后续再使用定时任务逐步淘汰旧的hash。
结构图示:
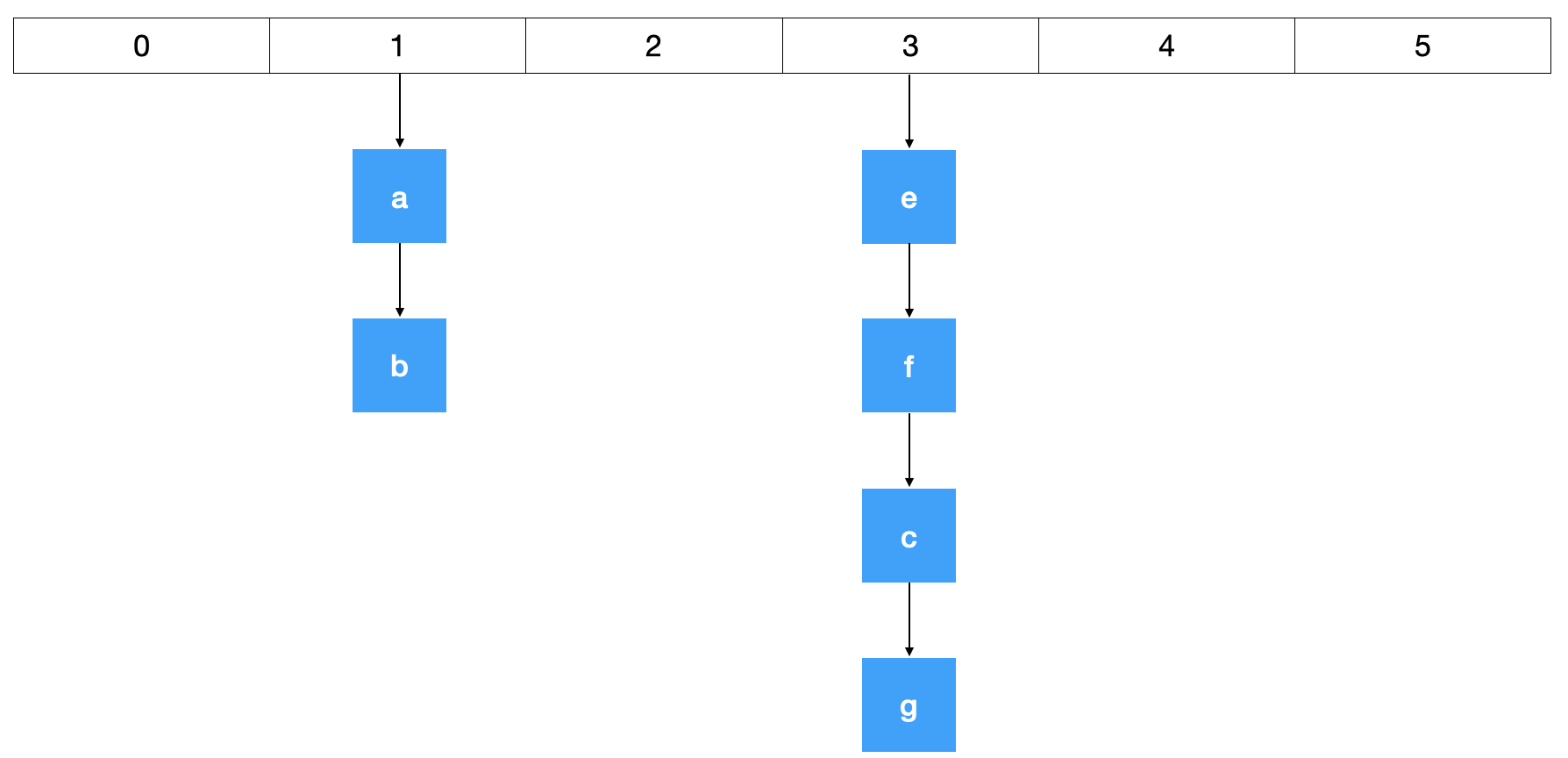
# 新增一个hash
hset testHash1 testKey1 valueString1
# 获取一个hash下的某个key的值
hget testHash1 testKey1
# 获取所有hash数据
hgetall testHash1
# 获取hash长度
hlen testHash1
Set
Set集合的底层实现为HashMap,以HashMap的key作为集合的值,而key所对应的value全部为Null,这样保证了Set内部数据的唯一性,又因为HashMap本身是无序的,所以Set是无序的结构。
# 新增一个集合元素
sadd testSet1 valueString1
# 查询一个集合所有元素
smembers testSet1
# 查询一个元素是否存在
sismember testSet1 valueString1
# 查询集合长度
scard testSet1
Zset
相较Set而言,Zset在确保集合元素的唯一性之外,同时增加了排序的特质。原理是在底层实现的时候多存了一个权重的字段,可以按照权重的大小进行排序。但是在数据结构的设计上却与Set大相径庭,为了实现高效率有序的插入,Zset使用了跳表的结构。当新元素要插入的时候可以依据多级的索引快速定位插入位置以保证集合的有序性。
结构图示:
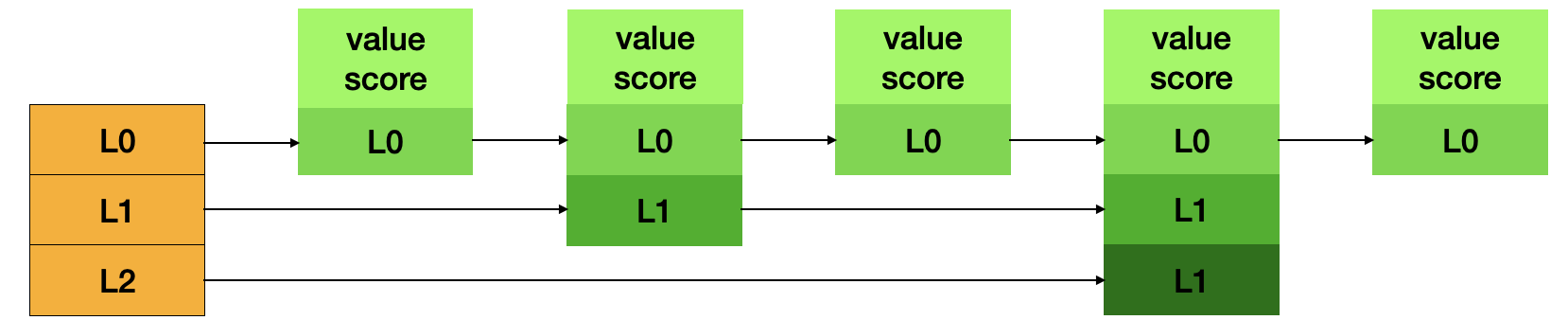
# 新增一个有序集合元素, 权重为9
zadd testZset1 9 valueString1
# 删除一个集合元素
zrem testZset1 valueString1
# 按照权重排序输出全部元素
zrange testZset1 0 -1
# 按照权重逆序输出全部元素
zrevrange testZset1 0 -1
# 集合长度
zcard testZset1
# 获取某元素的权重
zscore testZset1 valueString1
# 获取某元素的排名
zrank testZset1 valueString1
# 根据权重区间0-9遍历
zrangebyscore testZset1 0 9
文档信息
- 本文作者:KcJia
- 本文链接:https://blog.kcjia.cn/2020/07/02/redis-data-struct/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)